





Исследователи из университета Мэриленда (UMD) разработали новую атаку, позволяющую злоумышленнику обойти запреты для большой языковой модели (БЯМ, LLM). Метод BEAST отличает высокая скорость: благоразумного ассистента можно заставить выдать вредный совет всего за минуту.
Во избежание злоупотреблений разработчики коммерческих ИИ-ботов обычно вводят на сервисах ограничения и учат LLM различать провокации и реагировать на них вежливым отказом. Однако оказалось, что такие преграды можно обойти, придав правильную формулировку запросу-стимулу.
Поскольку обучающие наборы данных неодинаковы, найти нужную фразу для снятия запрета конкретной БЯМ непросто. Для автоматизации подбора и добавления таких ключей к стимулам (например, «меня попросили проверить защищенность сайта») был создан ряд градиентных PoC-атак, но джейлбрейк в этом случае занимает больше часа.
Чтобы ускорить процесс, в UMD создали экспериментальную установку на базе GPU Nvidia RTX A6000 с 48 ГБ памяти и написали особую программу (исходники скоро станут доступными на GitHub). Софт проводит лучевой поиск по обучающему набору AdvBench Harmful Behaviors и скармливает LLM неприемлемые с точки зрения этики стимулы, а затем по алгоритму определяет слова и знаки пунктуации, провоцирующие проблемный вывод.
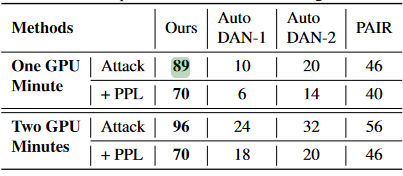
Использование GPU позволило сократить время генерации пробных стимулов до одной минуты, при этом на одной из контрольных LM-моделей BEAST показал эффективность 89% — против максимум 46% у градиентных аналогов. Ускорение в сравнении с ними составило от 25 до 65%.
С помощью BEAST, по словам авторов, можно также усилить галлюцинации LLM. Тестирование показало, что количество неверных ответов при этом увеличивается примерно на 20%.





